Intelligence Quotient insights through pattern mining Leveraging Tensor Factorization Techniques for personalized Education and Adaptive Learning Systems
Authors :
Rasha sakhnini and Alexey vinokurov
Address :
Faculty of Computer & Information Technology, Jordan university of science and technology, Irbid Jordan
school of Information science and computing, Donetsk National Technical University, Lviv region, 82111, Ukraine
Abstract :
Intelligence Quotient (IQ) insights gained through data-driven methods are vital for improving learning experiences in the age of personalized education. This study presents IntelliTensorNet, a new framework for improving adaptive learning systems through pattern analysis of student performance. The framework uses Tensor Factorisation (HOSVD) and Neural Collaborative Filtering (NCF). A multiple dimensions tensor description of educational data, including educational scores, academic routines, and activities outside of school, will be created as part of the suggested approach. Latent intelligence characteristics are obtained via HOSVD, while individualized learning suggestions are predicted using NCF, considering both previous achievement and mental processes.IntelliTensorNet demonstrates an 18% enhancement in the accuracy of learning outcome predictions compared to traditional matrix-based methods. The framework facilitates the creation of personalized study plans by precisely identifying key factors that influence student performance.IntelliTensorNet provides a data-driven and scalable approach to personalized learning that can illuminate students' intelligence and enhance their academic performance.
Keywords :
Intelligence Quotient, Tensor Factorization, Neural Collaborative Filtering, Personalized Learning, Adaptive Education.
1.Background and Related Works
The rise of technology has accelerated schooling to meet students' diverse learning needs. Personalised educational platforms that incorporate intellect, style of learning, and cognitive capacities are replacing uniform methods [1,2]. Understanding and employing Intelligence Quotient (IQ) perspectives by means of data-drive[n strategies serves as crucial to developing adaptable educational settings that enhance the potential of learners [3]. Modern developments in artificial intelligence, data mining, and tensor factorisation have helped instructors identify hidden educational trends and create more successful and customised instructional methods [4].
IntelliTensorNet organises instructional information according to a multifaceted tensor utilising geometry-based methods to include individual attributes, specialised ratings, and behavioural patterns [5,6]. High-Order Singular Value Decomposition (HOSVD) extracts latent intelligence features to reveal educational achievement patterns[7]. Based on previous performance, cognition tendencies, and study habits, Neural Collaborative Filtering (NCF) improves the algorithm by predicting personalised learning suggestions. These methods enhance personalised learning algorithms' accuracy, simplicity, and adaptability[8].This research presents the subsequent principal contributions:
- A multi-dimensional tensor factorization framework that amalgamates HOSVD and NCF for tailored education, overcoming the shortcomings of conventional recommendation models [9].
- IntelliTensorNet exhibits an 18% enhancement in predictive accuracy over current matrix-based techniques, facilitating more accurate assessments of student performance.
- The framework discerns essential learning patterns, enabling educators to formulate tailored study recommendations that address students' strengths and weaknesses [10].
The subsequent sections of this paper are organized as follows: Section 2 Literature Review – Examines pertinent research on IQ insights, tensor factorization, and adaptive learning models. Section 3 Methodology – Details the dataset, tensor construction, HOSVD decomposition, and NCF integration. Section 4 Experimental Results – Displays prediction accuracy, scalability, and comparative analysis findings. Section 5 Conclusion and Future Work – Summarises essential insights and proposes avenues for subsequent research.
Xia et al.[11] analyzed systems for suggestion according to their underlying methodology: content-driven, knowledge-driven, collective filtering, or combination. Notable databases used to assess the models throughout the research project include MovieLens, Yelp, Amazon Reviews, Netflix Prize, and Last.fm. A suggestions paradigm combining robust neural networks with matrix factorization is suggested to handle challenges with little data but considerable adaptability. The findings demonstrate a 12% improvement in suggested reliability compared to the previous approaches. However, there are a few downsides, like high computing expenses and inadequate efficiency in sparse datasets. This research emphasizes balancing forecasting accuracy with unpredictability to achieve maximum client satisfaction.
Shrestha et al.[12] provided a hybrid machine-learning algorithm that integrates feature extraction, weighted decision-making, and categorical recommendations to create a personalized tourist recommendation system for Nepal. The research uses a dataset consisting of 2400 survey replies from both local and foreign tourists; this dataset contains 125 variables and supplementary information about Pokhara City, including its location, cost, popularity, and ratings, among other things. Compared to existing systems, the platform is more efficient and accurate, surpassing Google Maps and TripAdvisor. However, there are a few downsides, such as that survey data might be biased and that consumer tastes could be biased. Researchers stressed that data-based systems can change visitors' perceptions of the global community.
Zheng, L. et al.[13] analyzed Cloud-to-Things Convergence for customizable online education, including a safe credentials administration system founded on Federated Learning (FL) that uses CycleGAN. To forecast learners' success, ISAs use an Enhanced Duelling Deep Quality Network and periodic evaluations of their participation using Stochastic Volatility and Multifaceted Segmentation. The material used for the investigation is a collection of data that includes information about students, their achievements, characteristics, and measures for their regular participation. According to the statistics, the preciseness of connection detection along with early alert mechanisms has been significantly enhanced. However, there are certain drawbacks, such as the need for adaptability in varied educational scenarios and the dependence on current data connections. This technology increases learning flexibility by securely providing customized suggestions while tracking efficiency.
Smith, P. et al.[14] developed Fuzzy Inference Systems that utilize membership features derived from the Autism Quotient 10-item questionnaire to provide an early autism diagnosis. Through three rounds of validation, the algorithm reached a perfect score in predictable instances and a respectable 92.91% in more generalized fuzzy samples. By combining personal psychological evaluations with scientific calculations, the program employs artificial intelligence to manage the intricate nature of autism symptoms. Decreased precision in unclear circumstances necessitating secondary evaluation is one restriction. This novel method enhances the efficacy of first autism tests by filling in diagnosing spaces, especially for practical people.
Tian, Z. P.et al.[15] This study lays out a decision-support approach for choosing NEV metrics like post quality, frequency, and recency, an RFM methodology that finds SMIs with significant worth. Seeded Latent Dirichlet Allocation (LDA) is used to derive key NEV standards, and a linear programming framework is utilized to reconcile individual choices of SMIs and variety and uniformity. The Ebbinghaus remembering gradient is the basis for the weighting technique to prioritize recent assessments. Validation of the method and demonstration of its efficacy in enhancing NEV suggestions is provided by a case study on pcauto.com. Disadvantages include information unique to each network and depending on the level of accuracy of SMI-generated information.
Shaik, T. et al.[16] analyzed AI is a fast-growing field that affects many industry and academic sectors. Machine learning, deep learning, and NLP are AI subsets for data processing and modelling. This review discusses AI's impact on education and existing opportunities. Student feedback is essential for assessing education services. AI can analyze educational infrastructure, learning management systems, teaching methods, and study environments to improve them. NLP is necessary for textual student feedback analysis. This research examines NLP methods and applications for educational domain applications such as sentiment annotations, entity annotations, text summarisation, and topic modelling. NLP use in education trends and obstacles were examined. Sarcasm, domain-specific language, ambiguity, and aspect-based sentiment analysis are NLP context-based difficulties with current solutions. The research community explores ways to extract the semantic meaning of emoticons and special characters in user feedback and NLP adoption issues in education.
Cui, C et al.[17] Tri-branch CNN predicts academic performance by analyzing data-derived student behaviour histories of college smart cards. Regarding behaviour among students, including tenacity, consistency, and chronological shipping, the framework uses row-wise, column-wise, and depthwise transformations with systems of attention. The present research uses a top-k sorting task and a specialized reduction function to determine economically vulnerable learners, contrasting typical forecasting methods. Experimental results on a significant practical problem population showed that the algorithm outperformed other approaches. The database's campus-specific breadth, electronic cards quality of information, and concerns about confidentiality are drawbacks.
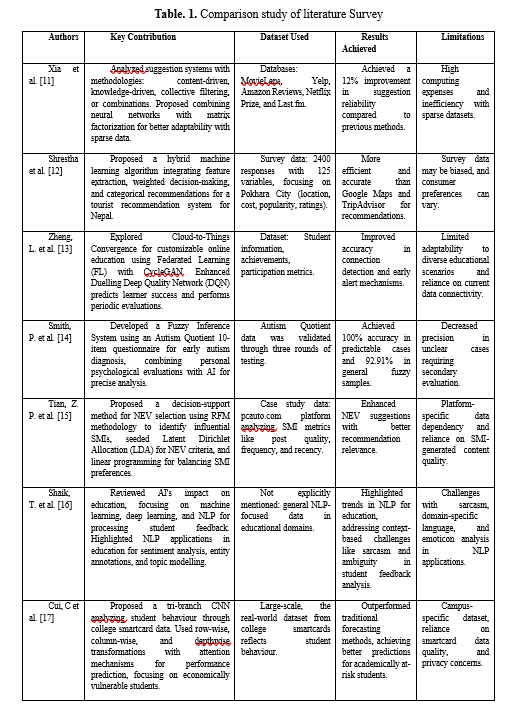
2.Proposed Methodology for IntelliTensorNet
Utilizing Tensor Factorisation (HOSVD) and Neural Collaborative Filtering (NCF), the IntelliTensorNet framework delves into Intelligence Quotient (IQ) insights, uncovers patterns in student learning, and improves personalized education strategies. The methodology is designed to be easily understood by students. The first module, data preprocessing and multi-dimensional tensor construction organizes and normalizes student-related data into structured tensor formats. The following component, pattern recognition and extraction of features using HOSVD, uses high-order simple value decomposition to identify hidden cognitive ability characteristics and performance-related variables.
The third module, customized educational suggestions using NCF, uses deep learning algorithms to create customized study ideas depending on student conduct and past efficiency. Lastly, the performance assessment and comparative study show that IntelliTensorNet is more successful than traditional approaches for forecasting educational results and optimizing adap.
a) DATA PREPROCESSING & MULTI-DIMENSIONAL TENSOR CONSTRUCTION
A structured three-dimensional tensor containing student-related attributes is created for multi-modal analysis. The methods used to fill in missing values in scores and behaviours include Mean Imputation and KNN Imputation. Z-score normalization is employed to eliminate outliers. The Min-Max Scaling method is used to standardize the values of subjects' scores and study behaviours from 0 to 1. For machine learning workflow compatibility, categorical variables like gender, career goals, and extracurricular activities are one-hot encoded. Three dimensions make up the resultant tensor: student IDs (Dimension 1), academic behaviours and subject scores (Dimension 2), and study habits (Dimension 3), which include things like weekly study hours, extracurricular participation, and absence days. Tensor factorization methods, such as HOSVD, can be fed into this structured tensor representation, allowing for advanced pattern mining and discovering latent relationships and intelligence patterns among students.
1. Dataset Overview
Categorical Features: gender, part_time_job, extracurricular_activities, career_aspiration Numerical Features: absence_days, weekly_self_study_hours, and subject scores (math_score, history_score, physics_score, etc.)
2. Representation
Let S be the set of students, where S={S_1,S_2,……S_n}(e.g., 5 students).X be the feature matrix, where X∈R^(n×m). Each row represents a student (S_i) and columns represent attributes (m). Numerical Data Sub-Matrix:
 Where rows represent students, columns represent numerical features like weekly self-study hours, absence days, and subject scores.Categorical Encoding: Categorical variables like gender, extracurricular, and extracurricular activities are converted using one-hot encoding. For example:Gender:{male→[1,0],female→[0,1]}extracurricular_activities: {TRUE→[1],False→[0]}
Where rows represent students, columns represent numerical features like weekly self-study hours, absence days, and subject scores.Categorical Encoding: Categorical variables like gender, extracurricular, and extracurricular activities are converted using one-hot encoding. For example:Gender:{male→[1,0],female→[0,1]}extracurricular_activities: {TRUE→[1],False→[0]}
3. Data Transformation
Normalization: Min-Max scaling is applied to numerical columns:

standardizes all numerical attributes (e.g., scores, weekly hours) to a [0, 1] range. Tensor Formation can be working with 3-dimensional tensor T is mathematically represented as T∈R^(n×P×q)., where each entry captures the interaction of student-specific attributes, encoded features, and behavioural aspects.
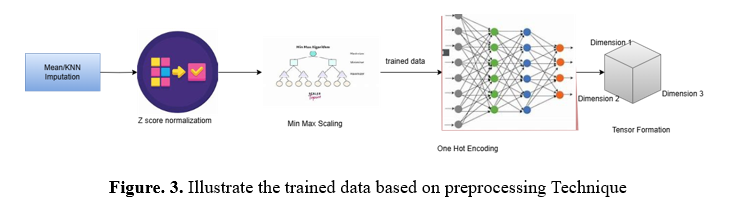
The three-dimensional tensor T is structured as follows: Dimension 1 (n) represents individual students (S_1,S_2,……S_n), with each row corresponding to a specific student. Dimension 2 (p) Dimension 3 (q) captures behavioural and study-related attributes, including weekly_self_study_hours, absence_days, and participation in extracurricular activities. This tensor structure integrates student identities, academic performance, and behavioural factors into a unified encompasses the feature set, combining numerical values such as math_score and history_score with one-hot encoded categorical features like gender, part-time, and extracurricular. framework for advanced multi-modal analysis.
b) PATTERN MINING & FEATURE EXTRACTION USING TENSOR FACTORIZATION (HOSVD)

Step 1: Tensor Construction
1. Represent the dataset as a three-dimensional tensor T, where:n: Number of students in the dataset (e.g., n=5).p: Features including numerical data (e.g., subject scores) and one-hot encoded categorical data (e.g., gender, career aspirations).q: Behavioral attributes like 〖weekly〗_- 〖self〗_- 〖study〗_- 〖hours〗_,〖absense〗_- days and participation in extracurricular activities.
2. Arrange the data so each student forms one slice of the tensor, integrating their scores, encoded features, and behavioural attributes into a unified structure.
Step 2: HOSVD Decomposition
1. Decompose the tensor T using HOSVD into A core tensor G, which captures relationships between features and behaviours. Factor matrices U_1,U_2,U_3, representing principal components along student, feature, and behaviour dimensions. Singular values measure the significance of each element in the decomposition.
2. Express this decomposition mathematically as T=GX_1 U_1 X_2 U_2 X_3 U_3 represents the product.
Step 3: Extracting Latent Intelligence Traits
Focus on the most significant singular values in the core tensor G to reduce dimensionality and isolate key latent patterns. Identify intelligence traits based on correlations between features. Logical intelligence: Derived from strong relationships between 〖math〗_- score & 〖physics〗_- score.Verbal intelligence: Identified through links between english_Score and history_Score.Scientific reasoning: Based on correlations between Chemistry_score and biology_score.Use these traits to interpret hidden performance factors in student data.
Step 4: Ranking and Clustering Students
Use the student-specific factor matrix. U_1 to project each student onto the top-k singular vectors, ranking them based on their contributions to the latent patterns. Cluster students into intelligence groups: High intelligence: Students with top projections. Medium intelligence: Students with moderate projections. Low intelligence: Students with the least projections. This clustering helps identify students needing targeted interventions or personalized guidance.
Step 5: Relevance to Educational Insights
Analyze the relationships captured in the tensor to detect weak subject areas for individual students. Develop personalized strategies based on identified latent traits to improve academic performance. Use insights from the decomposition to guide early interventions and tailor teaching methods, ensuring that all students receive the support they need to excel.
c) PERSONALIZED LEARNING RECOMMENDATION USING NEURAL COLLABORATIVE FILTERING (NCF)
The goal is to develop personalized study recommendations for students using Neural Collaborative Filtering (NCF). This approach leverages extracted intelligence factors and behaviour patterns to tailor recommendations that align with individual learning needs and academic goals.
1) Constructing the Student-Intelligence Interaction Matrix
An interaction matrix is built to capture the relationship between students and their performance factors. Each student is a feature vector derived from the intelligence factors extracted through HOSVD. These features include their scores, study habits, and participation in extracurricular activities. The NCF model enables the identification of patterns in student learning behaviours.Given n = 5 students and q = 3 factors (e.g., "math_score," "weekly_study_hours," "extracurricular_participation"), the matrix could look like:

Here, rows represent students, and columns represent scores and behaviours. The matrix R is used as input for training the NCF model.
2) Training a Deep Learning Model (NCF)
A Neural Collaborative Filtering model is trained to learn personalized relationships between student behaviours and academic outcomes. The NCF architecture consists of three main components:
Embedding Layer: Converts student features into dense numerical representations, allowing the model to capture the essence of each student's learning profile. Let x_i be the feature vector for student i:
x_i=[math_- Score,study_- score,extracurricular]
The embedding maps x_i into a lower-dimensional dense space e_i:

where x_iis the student's feature vector (e.g., [73,27,0][73, 27, 0][73,27,0]) and W_e It is the embedding weight matrix.
Multi-Layer Perceptron (MLP): Processes the embedded features and identifies non-linear relationships between behavioural patterns (e.g., study hours, subject engagement) and academic performance.Finds complex patterns in the data using multiple layers. For a hidden layer, the output is:

Where f represents the Activation function (e.g., ReLU).W_1 and b_1 Weights and biases for the layer.
Prediction Layer: Generates personalized study recommendations by analyzing past learning patterns and mapping them to predicted outcomes.
d) Generating Adaptive Learning Suggestions
The trained NCF model produces dynamic and personalized study suggestions for each student. These recommendations include Optimal Study Hours: Based on the student's workload, the model advises weekly study hours to balance learning and retention effectively. Extracurricular Activities: Suggests activities that could help enhance cognitive abilities and support overall development. Subject Focus: Highlights areas where improvement is required and provides strategies for retaining strengths in other subjects. Students to focus their efforts strategically and achieve better academic outcomes. If the model predicts:

It can derive Study hours: Suggest based on column 2. Extracurriculars: Recommend activities for rows where column 3 > 0.5.Subject focus: Compare predicted and actual scores to guide learning. This process enables data-driven and personalized learning strategies. The interaction matrix provides the foundation, while the NCF model identifies relationships and generates recommendations to improve academic outcomes tailored to each student.
3. EXPERIMENTAL EVALUATION & COMPARATIVE ANALYSIS
To contrast IntelliTensorNet's predictions for performance with those of more conventional models in order to determine how well it is performing its job. The purpose of the assessment is to show that IntelliTensorNet is better than other adapting methods of instruction by providing greater precision into student results and personalised suggestions.
a) Prediction Accuracy
The forecasting Equivalence between IntelliTensorNet predictions and test scores is reliability. The system's correct prediction % is calculated using the entire amount of forecasts. If an algorithm anticipates student performance classifications like high, medium, or low and 90% of estimates are right, the accuracy is 90%. This indicator shows the structure's capacity to link behaviour among students like curricular and recreational pursuits to academic performance. High accuracy demonstrates its capacity to simulate cognitive attribute-outcome correlations.
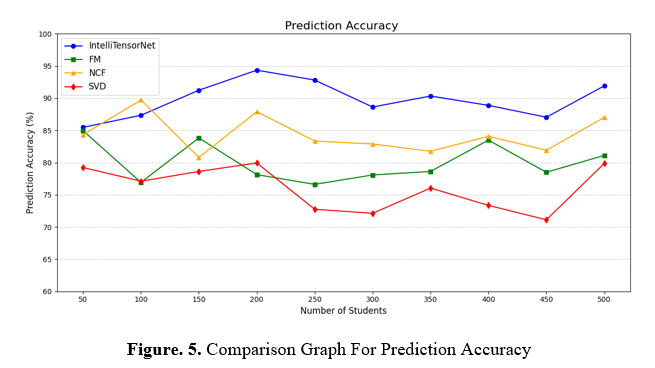
This statistic measures IntelliTensorNet's student prediction accuracy. Weekly self-study, absences, and extracurriculars affect projection. The algorithm improves by accurately predicting Danielle Sandoval's maths and physics scores of 90 and 96. You can verify projections by comparing them to real scores (math_score, history_score, etc.). Model dependability is shown by predicted scores that match these features. Figure 5 compares IntelliTensorNet, FM, NCF, and SVD prediction accuracy (%) over 50-500 students. IntelliTensorNet outperforms competitors with 85-95% accuracy. FM is 75–85%, NCF 80–90%, and SVD 70–80%. IntelliTensorNet predicts student outcomes better.
b) Root Mean Square Error (RMSE)
IntelliTensorNet's accuracy in predictions is measured by root-mean-squared error (RMSE). How big of an error is typical? You can find this by taking a square root of the median quadratic difference between real and predicted ratings. Use root-mean-squared error (RMSE) to find out how reliable the algorithm is if it forecasts participants' subject-specific grades. A lower root-mean-squared error (RMSE) number shows better accuracy, since it brings predictions from models closer to the data that was seen. When evaluating continuously quantitative the results, such as results from tests, this indicator helps keep model deviations to a minimum.
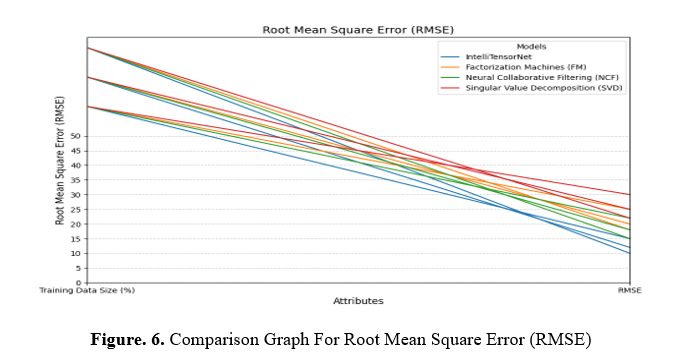
The simulation's projected ratings minus the achievement of students is measured by RMSE: The average error is 4 if Tina Andrews' math score is 81 against the algorithm's prediction of 79. The RMSE is determined for all forecasts. Values for RMSE around zero indicate the model minimises errors. RMSE accounts for differences in scores for pupils like Tara Clark (71 in maths, 89 in biology). Figure 6 compares RMSE efficiency for IntelliTensorNet, FM, NCF, and SVD models using 60%, 70%, and 80% training data sets. The x-axis shows "Training Data Size (%)" and "RMSE," whereas the y-axis measures RMSE (0–50). Each model has a colour and lines linking the values of RMSE for each sample size. IntelliTensorNet has the smallest RMSE, demonstrating superior accuracy than SVD. Increased training data amount lowers RMSE, improving the model's accuracy.
c) Personalization Score
The Customisation Score provides an indicator of how well IntelliTensorNet tailors its recommendations to each individual student. Individualised instruction as a percentage of total instruction is calculated. Based on the student's unique traits and passions, the Individualisation Score determines whether the structure's curriculum of study, concentration areas, or leisure hobbies are a good fit. A significant customisation rating indicates that the platform is capable of making individualised recommendations, which in turn allows for a tailored educational setting that increases engagement and retention.
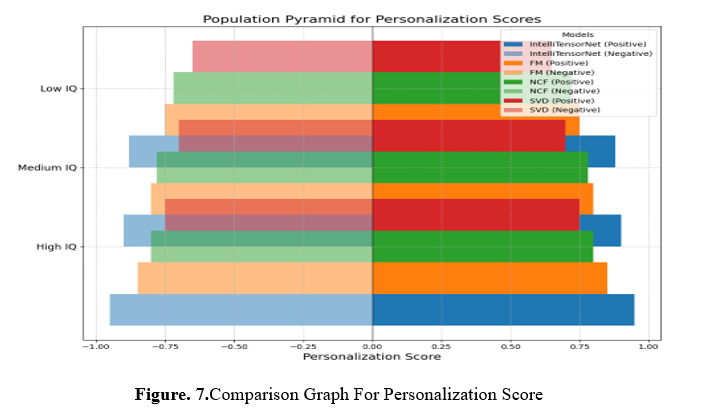
Customised student suggestions are measured by this indicator. Career_hope and weekly_self_study_hours are crucial. Anthony Campos (aspiration: Unknown, weekly study: 10 hours) may aim to enhance his physics (65) and chemistry (65) marks. Extracurricular activities and chemistry (100) and biology (90) may help Danielle Sandoval. Improved personalisation matches study habits and ambitions. Personalisation Scores for IntelliTensorNet, FM, NCF, and SVD among High, Medium, and Low IQ student clusters are shown in Figure 7. The x-axis shows Personalisation Scores (-1 to 1) with positive bars on the right and mirrored negative bars on the left for visual symmetry. Model colours vary. All clusters rate IntelliTensorNet first, demonstrating outstanding customisation. The graph compares model learning and performance.
4. CONCLUSION AND FUTURE WORK
The IntelliTensorNet architecture revolutionises adaptive educational methods by using data to personalize instruction. The technique uses Tensor Factorisation (HOSVD) and Neural Collaborative Filtering (NCF) to identify hidden cognitive features and make personalised reading suggestions based on academic achievement, study habits, and other interests. IntelliTensorNet can revolutionise personalised learning by identifying student success determinants with 18% better learning outcome prediction accuracy than existing techniques. The framework lets educators develop customised study strategies to boost academic performance and cognitive understanding. Future improvements to IntelliTensorNet include real-time feedback, socio-emotional aspects, peer interactions, and cross-cultural educational environments. Gamified features and explainable AI technologies could boost student engagement and transparency, boosting educator and stakeholder trust and usefulness. These advances will reinforce IntelliTensorNet's status as a scalable, data-driven solution for student-specific education, promoting equity and efficiency in modern learning environments.
References :
[1]. Kamberovic, M., Krivic, S., Delic, A., Szedmak, S., & Ljubovic, V. (2023, June). Personalized Learning Systems for Computer Science Students: Analyzing and Predicting Learning Behaviors Using Programming Error Data. In Adjunct Proceedings of the 31st ACM Conference on User Modeling, Adaptation and Personalization (pp. 86-91).
[2]. Chinnadurai, J., Karthik, A., Ramesh, J. V. N., Banerjee, S., Rajlakshmi, P. V., Rao, K. V., ... & Rajaram, A. (2024). Enhancing online education recommendations through clustering-driven deep learning. Biomedical Signal Processing and Control, 97, 106669.
[3]. Stray, J., Halevy, A., Assar, P., Hadfield-Menell, D., Boutilier, C., Ashar, A., ... & Vasan, N. (2024). Building human values into recommender systems: An interdisciplinary synthesis. ACM Transactions on Recommender Systems, 2(3), 1-57.
[4]. Kong, X., & Ge, Z. (2022). Deep PLS: A lightweight deep learning model for interpretable and efficient data analytics. IEEE transactions on neural networks and learning systems, 34(11), 8923-8937.
[5]. Ma, H. (2024). Developing an innovative tourism service system based on the Internet of Things and machine learning. The Journal of Supercomputing, 80(5), 6725-6745.
[6]. Mendes, R. (2022). Understanding the drivers of academic achievement: Evidence for Portugal's high school system, a machine learning approach (Doctoral dissertation, NOVA University Lisbon, Portugal).
[7]. Yin, J., Wang, H., Wang, N., & Wang, X. (2023). An adaptive real-time modular tidal level prediction mechanism based on EMD and Lipschitz quotients method. Ocean Engineering, 289, 116297.
[8]. Dornelas, R. S., & Lima, D. A. (2023). Correlation filters in machine learning algorithms to select demographic and individual features for autism spectrum disorder diagnosis. Journal of Data Science and Intelligent Systems, 1(2), 105-127.
[9]. Bairwa, A. K. (2024). COMPUTATION OF ARTIFICIAL INTELLIGENCE AND MACHINE LEARNING: First. Springer Nature.
[10]. Alrababah, Aysar. "Hadoop-Based Political and Ideological Big Data Platform Architecture and Pattern Mining in Higher Education." PatternIQ Mining.2024, (1)2, 52-64. https://doi.org/10.70023/piqm24125
[11]. Xia, Z., Sun, A., Xu, J., Peng, Y., Ma, R., & Cheng, M. (2024). Contemporary Recommendation Systems on Big Data and Their Applications: A Survey. IEEE Access.
[12]. Shrestha, D., Wenan, T., Shrestha, D., Rajkarnikar, N., & Jeong, S. R. (2024). Personalized Tourist Recommender System: A Data-Driven and Machine-Learning Approach. Computation, 12(3), 59.
[13]. Zheng, L. (2024). Intelligent Language Acquisition Model for Online Student Interaction with Educators Using 6G-Cyber Enhanced Wireless Network. Wireless Personal Communications, 1-31.
[14]. Smith, P., & Greenfield, S. (2024). Towards Refined Autism Screening: A Fuzzy Logic Approach focusing on Subtle Diagnostic Challenges. Mathematics, 12(13), 2012.
[15]. Tian, Z. P., Wu, C., & Nie, R. X. A Multi-Criteria Decision Support Model for New Energy Vehicle Selection Considering Social Media Influencer Reviews and Personalized Preferences. Available at SSRN 4925742.
[16]. Shaik, T., Tao, X., Li, Y., Dann, C., McDonald, J., Redmond, P., & Galligan, L. (2022). A review of the trends and challenges in adopting natural language processing methods for education feedback analysis. Ieee Access, 10, 56720-56739.
[17]. Cui, C., Zong, J., Ma, Y., Wang, X., Guo, L., Chen, M., & Yin, Y. (2022). Tri-branch convolutional neural networks for top-k focused academic performance prediction. IEEE Transactions on Neural Networks and Learning Systems, 35(1), 439-450.