RECENT ADVANCES AND APPLICATIONS OF APRIORI ALGORITHM IN EXPLORING INSIGHTS FROM HEALTHCARE DATA PATTERNS
Authors :
Ali Al-Sarayrah
Address :
School of management and logistics, German Jordanian University
Abstract :
The growing accessibility of extensive healthcare datasets has highlighted the need for solid methods for discovering significant connections and trends that can guide clinical decision-making and management of healthcare practices. The Apriori algorithm, recognized for effectively detecting common item groups and connection rules, presents a hopeful method to tackle these issues. This paper explores the latest progress and real-world uses of the Apriori algorithm in analysing patterns in healthcare data. By thoroughly examining the literature and case studies, this paper proposes the Healthcare Analytics and Insight Framework (HAIF), in which the Apriori algorithm can find meaningful connections and trends in healthcare data. The information obtained by Apriori-based analysis can help improve individualized patient care, resource management, and predictive analytics, leading to better healthcare delivery and patient outcomes. Moreover, the research investigates several challenges and opportunities associated with utilizing the Apriori algorithm for medical data analysis. It highlights the need of interpretability, adaptability, and ethical concerns in examining healthcare data, underlining the importance of conscientious data handling and security protocols. This research offers essential information about how the Apriori algorithm can reveal valuable insights from patterns in healthcare data that can help improve data-driven medical decision-making and patient-focused care delivery strategies.
Keywords :
Healthcare data; Pattern mining; Apriori algorithm; Insights; Clinical decision making; Healthcare management; Patient care.
1.Introduction
With data mining, healthcare companies may be able to predict patterns in patient behaviour and medical conditions by analyzing several prospects and making connections between seemingly unrelated pieces of information. The raw data collected from healthcare organizations is vast and diverse. It must be gathered and organized, and its integration makes it possible for healthcare information systems to integrate cohesively [1]. In data mining, clustering divides or segments data items/points into meaningful groupings and clusters by assembling objects that are statistically similar to one another [2]. Among the often-employed techniques to explore the relationships between (1) prescription and prescribers (in this case, doctors) and (2) symptoms and drugs for a specific illness in hospitals is the data correlation analysis method [3]. Most research has examined the causes of commercial truck crashes using parametric models. Its shortcomings have been noted to include predefined assumptions and underlying linkages between variables that are independent and dependent [4]. Data mining is the process of discovering patterns or valuable information in large sets of data that may be beneficial for decision-making. The Apriori algorithm is a popular and widely used rule of association discovery data mining techniques [5].
Associative rule mining has been increasingly popular for aiding in disease diagnosis and decision-making within the healthcare sector [6]. Algorithms for machine learning are a strong asset in the medical field, particularly when analyzing clinical records to find important information and guiding research findings. One machine-learning method for identifying hidden patterns in data is association rule mining [7]. Making intelligent decisions in various application fields might be facilitated by deriving knowledge or practical insights from these data. In data science, sophisticated analytics techniques such as machine learning and predictive modelling can offer valuable insights or enhanced data understanding, automating and intelligently processing computations [8]. Clinical data repositories, or Electronic Health Records (EHR), constitute the foundation of this study. Heterogeneous data paradigms that can apply to any data recorded in a healthcare context are included in electronic health records (EHRs) [9]. The phrase "Administrative health Recordings" (AHR) refers primarily to the portion of Electronic Health Records (EHRs) that are gathered for administrative reasons and contain significant data about how patients engage with the healthcare system. AHRs differ from other data modalities that EHRs capture in several distinctive ways [10]. AHRs are filled with comprehensive patient cohort data in organized, classification-encoded records. The main contribution of the paper is,
- To propose the Healthcare Analytics and Insight Framework (HAIF), in which the Apriori algorithm can find meaningful connections and trends in healthcare data.
- To investigate challenges and opportunities associated with utilizing the Apriori technique in healthcare data analysis.
- To emphasize the significance of interpretability, flexibility, and ethical issues in analyzing healthcare datasets, stressing the relevance of responsible data management and security measures.
- To offer essential information about how the Apriori algorithm can reveal valuable insights from patterns in healthcare data that can help improve data-driven medical decision-making and patient-focused care delivery strategies.
The rest of the research is divided into the subsequent sections: Section 2 examines previous research, Section 3 outlines the process of the HAIF structure, Section 4 talks about the findings, and lastly, Section 5 presents the conclusions of the work and future research directions.
2. Related works
Patel et al. [11] suggested using polygenic scores to evaluate the genetic risk of heart disease, which combines data from several DNA variations into one measure. These more recent polygenic scores can pinpoint up to 8% of people with three times the usual risk by looking at genetic differences, exceeding the predictive ability of ancestral records or clinical risk markers. It also points out the need for further research to ensure these risk estimates work well for different traditional backgrounds, determine how they can be used in clinical settings, and confirm their usefulness through randomized trials. Mohamad et al. [12] proposed the Apriori method, which analyses the connections between various elements that lead to accidents. This examination aids in creating strategies to lower accident rates, minimize economic and human losses, and enhance the effectiveness of the healthcare system. The findings indicate various factors that raise the likelihood of fatalities, including being male, exceeding speed restrictions, riding a motorcycle, operating on straight highways, encountering dry roads, and having good weather. Wilson et al. [13] proposed the process of hashing, which involves utilizing a function known as a hash to decrease the size of the group of potential objects, is frequently employed. This work suggests a specific hashing algorithm for a set of d items. The effectiveness of the Apriori algorithm is improved by utilizing the hash function. Kohzadi et al. [14] proposed common patterns in the data from the Kashan Trauma Center by using an enhanced algorithm that incorporates the automatic determination of minimal support and includes weights. The present study aims to include both variable weighing and automatic minimum support computation. A thorough analysis of these variables provides valuable insights into how well each study works.
Seghieri et al. [15] created a new approach by combining data reduction and algorithms for clustering to find patterns of persistent illnesses that are expected to happen together in individuals with multiple chronic conditions. Research shows that (i) cardio-metabolic, hormone-related, and neuro-degenerative disorders share a typical pattern in many health issues, and (ii) the presence and classification of diseases vary between age groups as well as between females and males. Moreover, examining time-based patterns of illness can improve risk forecasts for progressive long-term health issues. Alharith et al. [16] proposed this summary recommends using data mining methods such as frequent pattern evaluation and mining association rules to reveal undisclosed patterns in cancer information. The study intends to help healthcare practitioners diagnose and treat cancer more effectively using support and confidence measures. Gender differences in cancer detection show that women are more at risk, and common types of cancer such as breast, prostate, ovarian, esophageal, and cervical cancers are significant discoveries. Tenepalli et al. [17] proposed exploring IoT-based healthcare systems utilising machine learning algorithms to forecast chronic conditions such as diabetes, breast cancer, heart disease, and more. The study also suggested a comparison of machine learning methods for illness detection. It also recognised the current problems and difficulties in machine learning and IoT-based medical systems.
Pal et al. [18] demonstrated various nonlocal mathematical models in biology and life sciences. The primary emphasis was placed on the origins, progress, and applications of these models. The study also discussed alternative modeling techniques for stem cells derived from malignancies and tumor cells that are frequently employed to simulate cell movement, development, and tumors lacking blood arteries in any area of the body. The paper gave a detailed overview of new developments and pointed out potential future paths in this quickly growing area. Aljehani et al. [19] proposed a structured evaluation of existing research on metaheuristic algorithms that deal with difficulties related to Privacy-Preserving Association Rule Mining (PPARM). It examines previous research, offering perspectives on several metaheuristic methods to address PPARM issues. The review expands its examination to include the most recent practical methods, emphasizing the variety of current metaheuristic algorithms in the PPARM framework. Papageorgiou et al. [20] proposed important insights into athletic injuries and recovery, offering players and league officials essential information. This research will influence how player health is managed, and team strategies are developed, setting the foundation for future studies on the lasting impacts of injuries and the incorporation of technology in monitoring player health.
3. Proposed work
One of the most important first steps in performing an extensive analysis of healthcare information is locating and gaining access to different data sources. These resources cover a broad spectrum of data and sources, each providing unique insights into various facets of patient care, medical research, and healthcare delivery. EHRs [21], which include detailed data on patient demographics, medical histories, diagnoses, prescriptions, test findings, and treatment plans, are a significant source of healthcare data. Hospitals, clinics, and medical facilities often gather and retain EHR data, which offers important insights into patient care routes, treatment outcomes, or disease management procedures. Medical imaging data, which includes information from MRIs, CT scans, X-rays, and various other diagnostic modalities, is another crucial source of healthcare data. These imaging tests produce large volumes of data, which help medical professionals diagnose and visualize a wide range of illnesses, track the course of diseases, and assess how well treatments work.
Patient-generated medical information from wearable technology, mobile apps, and remote monitoring systems, in addition to clinical data, provides insights into people's health behaviours, levels of activity, and vital signs. These data sources make it possible to continuously monitor patients' health conditions, making it easier to identify health problems early and provide individualized interventions. Data from clinical trials can be gathered from academic institutions, pharmaceutical corporations, and government regulatory bodies to shed light on the efficacy, safety, and effectiveness of medical interventions and treatments. These datasets help to inform decisions in clinical practice and medication development by providing data on study participants, actions, outcomes, adverse reactions, and follow-up assessments. Figure 1 represents the flow diagram of the proposed work of the HAIF framework.
a. Healthcare Analytics and Insight Framework (HAIF)
Data preprocessing
Preprocessing of the healthcare datasets is required before using the Apriori technique. Preprocessing entails actions like these:
- Taking care of missing values: Use imputation techniques or a suitable placeholder to fill in the gaps.
- Eliminating duplicates, fixing mistakes, and resolving discrepancies in the data is known as data cleaning.
- Data transformation: Prepare the dataset (typically in a transactional format, as each row corresponds to a transaction) for use with the Apriori algorithm.
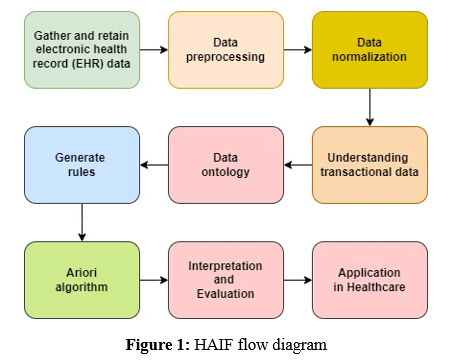
Understanding transactional data
In the healthcare industry, transactional data refers to various elements that record patient contacts and medical services rendered while a patient is in a facility. Every patient visit is a transaction that contains information on the healthcare provider seen, the date, and the time. All medical operations, from simple check-ups to intricate surgeries, are documented using specific codes or descriptions. Prescribed medications treat various illnesses or symptoms, depending on the ailment and how often they are used. Diagnoses provide information about the patient's health and the reason for the visit. They are usually coded using (International Classification of Disease) ICD-10 classifications. The results of laboratory tests, such as imaging investigations, biopsies, and blood tests, are used to assess health status and inform treatment decisions. These elements come together to create a comprehensive dataset essential for research, quality improvement, clinical decision-making, and the creation of healthcare policies.
Transactional data analysis in healthcare is pivotal for clinical decision-making, quality improvement, research, and policy development. It enables informed patient care, treatment options, and disease management decisions. Identifying trends and patterns supports quality enhancement and resource allocation within healthcare organisations. Analysing data aids research, epidemiological studies, and population health management by revealing disease prevalence, treatment outcomes, and healthcare utilization. Moreover, it informs policy development, resource planning, and public health interventions to improve healthcare delivery and outcomes. Techniques like the Apriori algorithm extract actionable insights, fostering continuous enhancements in patient care, healthcare delivery, and population health management.
Data ontology
There are two categories of context: low-level and high-level contexts in communication and applications. Unlike a high-level context, that is implied and comes from low-level settings, low-level context is measured and observed explicitly. Context ontology modelling and interpretation according to the domain are necessary to produce high-level context semantically. Shared conceptualisations like ontology make creating a semantic, smooth, high-level context for contextual-aware services more accessible. It facilitates logic inference, reuse, and knowledge exchange. The definition of classes, associations, and subject constraints is provided by ontology, which also enables syntactic and semantic interchange. Together with domain-specific ontologies, general and domain classes compose context ontology. In computer systems, semantically correct rules and inference creation for context-aware services are made possible by ontology, particularly when utilizing the Web Ontology Language (OWL). To improve interoperability and knowledge reuse, physiological data that describe physiological parameters can be organized and reused via context ontology.
Apriori algorithm
Classic algorithms like the Apriori algorithm mine frequently occurring itemsets and produce association rules from transactional datasets.
• Generating candidate itemsets
- Make First-Size Candidate Itemsets: The program first counts the instances of distinct components (singletons) by scanning the dataset. Finding frequently occurring items that satisfy a minimum support level is done using these counts.
- Join Step: The method creates potential itemsets with size k by connecting frequent itemsets with size k-1 (in which k is the itemset size). By merging preexisting frequent itemsets, it generates new candidate itemsets.
- Prune Step: After generating candidate itemsets, the process eliminates those candidate itemsets that have non-frequent groups of size k-1. By trimming, the range of search is reduced, leading to improved efficiency.
• Scanning transactions
- Counting Occurrences: The algorithm searches the transactional dataset to determine the frequency of a candidate item set.
- Updating Support Count: The algorithm changes the number of occurrences of each potential item set based on the actions where it appears. The percentage of events in the dataset, which includes the itemset, is represented by the term "support."
• Generating association rules
- Finding Frequent Itemsets: After adjusting the number of supports for each candidate group of items, the process identifies common item groups that meet the minimum support level selected by the user.
- Association rules are produced from the frequently occurring itemsets using user-defined criteria like lift, confidence, and support. These measures aid in evaluating the importance and potency of the correlations among the items.
Support measures an itemset's frequency of occurrence in the dataset, indicating how common it is among transactions. Greater support values indicate stronger correlations. Confidence assesses how likely a rule will be true for the antecedent, indicating the magnitude of the connection between the prior and the consequent. Lift calculates the relative frequency of the resultant given the antecedent, emphasising positive correlations if the number is greater than 1. The Apriori algorithm's valuable patterns influence decision-making in the retail, e-commerce, and healthcare industries in transactional datasets, which analyze association rules established from frequent item sets.
𝑨𝒍𝒈𝒐𝒓𝒊𝒕𝒉𝒎 𝟏: Apriori algorithm is represented in pseudocode:
function apriori(dataset, min_support_threshold, min_confidence_threshold):
// Initialize an empty list to store frequent itemsets
frequent_itemsets = []
// Generate frequent itemsets of size 1 (singletons)
frequent_itemsets_1 = generate_frequent_itemsets_1(dataset, min_support_threshold)
frequent_itemsets.append(frequent_itemsets_1)
k = 2
while frequent_itemsets[k - 2] is not empty:
// Generate candidate itemsets of size k
candidate_itemsets = generate_candidate_itemsets(frequent_itemsets[k - 2])
// Prune candidate itemsets
pruned_candidate_itemsets = prune_candidate_itemsets(candidate_itemsets, frequent_itemsets[k - 2])
// Count occurrences of pruned candidate itemsets in the dataset
count_occurrences(pruned_candidate_itemsets, dataset)
// Update support count of pruned candidate itemsets
update_support_count(pruned_candidate_itemsets)
// Select frequent itemsets that meet the support threshold
frequent_itemsets_k=select_frequent_itemsets (pruned_candidate_itemsets, min_support_threshold)
// Add frequent itemsets of size k to the list
frequent_itemsets.append(frequent_itemsets_k)
k = k + 1
// Generate association rules from frequent itemsets
association_rules = generate_association_rules(frequent_itemsets, min_confidence_threshold)
return frequent_itemsets, association_rules
function generate_frequent_itemsets_1(dataset, min_support_threshold):
// Count occurrences of individual items (singletons)
// Select items with support >= min_support_threshold
return frequent_itemsets_1
function generate_candidate_itemsets(frequent_itemsets):
// Join frequent itemsets of size k-1 to generate candidate itemsets of size k
return candidate_itemsets
function prune_candidate_itemsets(candidate_itemsets, frequent_itemsets):
// Eliminate candidate itemsets that contain subsets of size k-1 which are not frequent
return pruned_candidate_itemsets
function count_occurrences(candidate_itemsets, dataset):
// Count occurrences of candidate itemsets in the dataset
// Update the support count of each candidate itemset
return updated_candidate_itemsets
function update_support_count(candidate_itemsets):
// Update the support count of candidate itemsets based on transactions
return updated_candidate_itemsets
function select_frequent_itemsets(candidate_itemsets, min_support_threshold):
// Select frequent itemsets that meet the support threshold
return frequent_itemsets
function generate_association_rules(frequent_itemsets, min_confidence_threshold):
// Generate association rules from frequent itemsets
return association_rules
The Apriori technique for mining common itemsets and producing rules for association from transactional datasets is implemented step-by-step in the pseudocode. For frequent items, it starts with an empty list and gradually creates candidate items with progressively larger sizes. Frequent itemsets are recognized and these itemsets are trimmed based on support thresholds. A systematic method for deriving significant insights from data is provided by generating association rules dependent upon predetermined confidence thresholds.
Interpretation and Evaluation
Determining valuable insights from the data requires interpreting and assessing the association rules produced by the Apriori algorithm.
• Examining Generated Rules
- Find Significant Correlations
- Analysing Patterns:
Analysts examine the association rules to find patterns and connections among the objects. This entails being aware of the rules' consequences within the domain. In medicine, for instance, correlations between drug regimens and patient results can disclose beneficial therapeutic approaches or possible side effects.
Analysts carefully examine the rules to comprehend the patterns that underlie the relationships. They investigate which objects usually co-occur and under what situations. This knowledge aids in decision-making and the creation of plans for enhancing results.
• Threshold-Based Filtering:
- Lift, Support, and Confidence Limits:
- Fine-tuning Filters:
Predetermined lift, confidence, and support thresholds are used to filter rules. The intended level of relevance, business needs, and domain expertise are considered while determining these criteria. Rules that don't fit these criteria could be viewed as less instructive or meaningful.
Analysts can repeatedly change the threshold values to improve the choice of rules. This procedure aids in concentrating on connections that are more significant and useful in the given situation.
• Analysis of Refinement:
- Input and Subject Matter Expertise:
- Iterative Process:
Stakeholder and subject matter expert feedback is essential for improving the analysis. Stakeholders assist in determining which associations are most important for decision-making and offer insights into the practical effects of the regulations.
Several steps are involved in interpreting and assessing association rules. Analysts are constantly improving their comprehension of the data and the conclusions they draw from it. They alter criteria, investigate new data dimensions, and incorporate fresh information to gain a more profound knowledge of the underlying patterns and correlations.
Applications in healthcare
In medicine, correlations between specific medical procedures and patient outcomes may be found by examining association rules generated from patient data. Healthcare professionals could be prompted to reevaluate their surgical protocols or choose patients' criteria if a rule indicates a high link between a specific surgical technique and post-operative problems. The association rules are made more effective and actionable through ongoing refinement of the analysis and integration of physician feedback, improving patient outcomes.
The Apriori method finds useful relationships in healthcare datasets where medical procedures are items and patient visits are transactions. Procedure Y is commonly performed on patients with disease X, suggesting common treatment patterns. Similar to this, prescriptions for drugs A and B frequently match, indicating co-management techniques or drug synergies. Additionally, the algorithm finds groups of related medical operations routinely carried out during visits, which helps with resource optimization and care coordination. These affiliations enable medical professionals to customize care regimens, reduce hazards, and improve patient outcomes. Using data-driven insights, healthcare professionals can reduce unfavourable outcomes, enhance patient satisfaction, and optimize the way they give treatment. In the end, the Apriori algorithm is a vital resource for identifying complex patterns in healthcare datasets, empowering clinicians to make well-informed decisions that enhance patient care and the delivery of healthcare as a whole.
Interpreting and assessing association rules entail a comprehensive study, screening according to predetermined cutoff points and iterative improvement driven by input and domain knowledge. Through this process, unprocessed data is transformed into useful insights that guide choices and promote advancements across a range of industries.
4. Results and discussion
a. Support
In association rule mining, support is a key performance indicator that measures how frequently an itemset appears in a dataset. It aids in determining the importance and potency of correlations among objects. The percentage of dataset transactions that include an itemset is used to determine the itemset's support. Mathematically, support of an itemset is given by equation (1) as,
Support (X)=(Number of transactions containing X)/(Total number of transactions) (1)
The percentage of transactions whereby an itemset appears is known as its support. Take a dataset with 100 transactions, for instance, and let's say we wish to determine the support of the itemset {A,B} (items A and B). The support of {A,B} is: if the itemset {A,B} occurs in 20 transactions, then
Support{A,B}=20/100=0.2 (2)
From equation (2), the support of {A,B} is 0.2 or 20%. Stronger relationships between the items are suggested by higher support values, which show that the itemset occurs frequently in the dataset. Lower support values, on the other hand, suggest that the itemset has become less prevalent among the dataset.
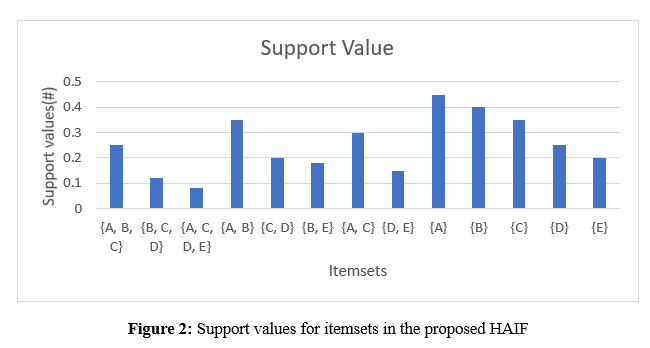
The figure 2 shows that support values help with pattern recognition, clinical choice-making, and quality improvement by providing information about the frequency of health events or item combinations in healthcare datasets. They act as analytical resources for figuring out illness trends, treatment regimens, and patterns of healthcare use. In line with enhancing patient outcomes, optimizing resource use, and resolving healthcare inequities, the content highlights the practical significance of support values in healthcare analytics, which is essential for well-informed decision-making and management.
Frequent itemsets must be identified to generate relevant association rules within data mining activities, and support plays a critical role in this process. High-support value items are more likely to establish meaningful linkages and offer insightful information for decision-making across various industries, including marketing, retail, and healthcare.
b. Confidence
In association rule mining, confidence is a crucial statistic that evaluates the dependability and strength of the relationship between a rule's antecedent and consequent. It calculates the conditional probability that, if the antecedent occurs, the resultant will also appear.
In mathematical terms, the confidence about a rule X→Y is expressed in the following equation (3),
Confidence(X→Y)=(Support(X∪Y))/(Support(X)) (3)
Stated differently, confidence is the probability that the subsequent (Y) will happen in transactions involving the antecedent (X).
Let's take an example where we have a rule {A}=>{B}that indicates that item B is probably going to occur in a transaction if item A does. If the confidence level of this rule is 0.8, it indicates that item B appears in 80% of all occurrences when item A does.
Strengthening correlations between the prior and subsequent events are shown by higher confidence levels. The consequent always happens when the preceding event is present, according to a confidence quantity of 1. Lower confidence scores, on the other hand, point to weaker correlations or less trustworthy forecasts.
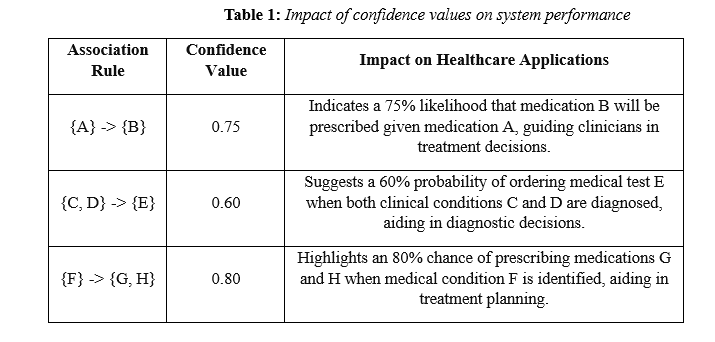
In the healthcare industry, confidence values support treatment planning, allocation of resources, clinical decision-making, and quality improvement. Based on patterns in the data, they represent the probability of certain events or courses of action. Although this data is organized in Table 1, its practical application necessitates clinical knowledge and careful interpretation to maximize patient care and the organisation's efficiency.
Confidence is an essential indicator for assessing the effectiveness and value of association rules. It can offer insightful information for decision-making across various fields, including market basket analysis, systems for recommendation, and healthcare data analysis. It assists in identifying rules that are most likely to be true. High-confidence associations are more reliable and helpful in informing corporate plans and decision-making processes since they are more actionable and trustworthy.
c. Lift
A statistical metric called lift is employed in mining association rules to estimate the importance and intensity of the relationship between a rule's antecedent and consequent. It gives information about how much more probable the subsequent event is to occur about the antecedent than it is to occur generally in the dataset.
The proportion of the visible backing for a regulation (say X→Y) to the anticipated backing (say X→Y) if the antecedent or consequent are independent is called the lift of the rule. In terms of math, it is defined by equation (4) as,
Lift(X→Y)=(Support(X∪Y))/(Support(X)×Support(Y)) (4)
Put more, lift quantifies the extent to which the antecedent's (X) occurrence influences the consequent's (Y) occurrence above and beyond what would be predicted by chance alone.
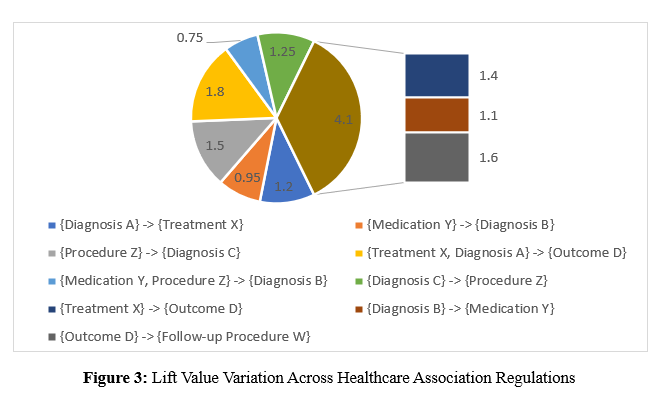
Figure 3 shows several association rules and their accompanying lift values obtained from healthcare datasets. The lift values indicate the strength and importance of correlations between healthcare-related factors or occurrences. If the elements occur together more often than expected, a lift value more than 1 indicates a positive relationship, whereas a lift value less than 1 indicates a negative or neutral relationship.
Understanding lift values
- Lift = 1: Denotes the independence of the preceding and following events from one another. One's occurrence does not affect the other's occurrence.
- Lift > 1: Denotes a favourable correlation between the preceding and subsequent variables. When the prior event is present, the next event is more probable to occur than it would otherwise.
- Lift <1: Denotes a lousy correlation between the antecedent and the consequent. Compared to its regular occurrence, the subsequent event is less likely to take place when the prior event is present.
High lift values indicate stronger links between the previous and subsequent events, whereas low lift values indicate weaker correlations. Lift values more extensive than one are typically regarded as significant and suggestive of intriguing linkages or patterns in the data.
As it assists in identifying significant associations between elements that go above what would be predicted by random chance, lift is a crucial statistic in association rule mining. Concentrating on significant and practical correlations helps analysts make wise choices and extract insightful information from the data.
5. Conclusion
In summary, the increasing availability of large-scale healthcare datasets demands the development of solid techniques for identifying important relationships and patterns that will effectively inform clinical judgment and healthcare administration. The Apriori algorithm is an effective method for identifying frequent item groups and connecting rules in medical data. This paper presents the Healthcare Analytics and Insight Framework (HAIF), which uses the Apriori algorithm to extract relevant insights by examining recent advancements and practical implementations. This information can improve patient outcomes and healthcare delivery by enabling predictive analytics, optimizing resource allocation, and enhancing tailored patient care. The study also highlights the benefits and drawbacks of applying the Apriori algorithm to healthcare data mining, highlighting the significance of interpretability, adaptability, and ethical issues. It emphasizes the importance of managing data responsibly and having robust security measures to guarantee medical records' confidentiality and integrity. Healthcare professionals can enhance patient-focused methods for providing care and empower data-driven medical decision-making by utilizing the Apriori algorithm to extract significant insights from healthcare data patterns. In the future, more work will be done on improving data analysis methods, incorporating real-time data sources, using statistical analysis, addressing ethical issues, encouraging interdisciplinary research, and assessing long-term effects.
References :
[1] Sornalakshmi, M., et al. "Hybrid method for mining rules based on enhanced Apriori algorithm with sequential minimal optimization in the healthcare industry." Neural Computing and Applications (2020): 1-14.
[2] Chaudhry, Mahnoor, et al. "A systematic literature review on identifying patterns using unsupervised clustering algorithms: A data mining perspective." Symmetry 15.9 (2023): 1679.
[3] Zheng, Yi, et al. "Application of Apriori improvement algorithm in asthma case data mining." Journal of Healthcare Engineering 2021 (2021).
[4] Hong, Jungyeol, Reuben Tamakloe, and Dongjoo Park. "Discovering insightful rules among truck crash characteristics using apriori algorithm." Journal of advanced transportation 2020 (2020): 1-16.
[5] Santoso, M. Hamdani. "Application of Association Rule Method Using Apriori Algorithm to Find Sales Patterns Case Study of Indomaret Tanjung Anom." Brilliance: Research of Artificial Intelligence 1.2 (2021): 54-66.
[6] Odu, Nkiruka Bridget, et al. "How to implement a decision support for digital health: Insights from design science perspective for action research in tuberculosis detection." International Journal of Information Management Data Insights 2.2 (2022): 100136.
[7] Dehghani, Mohammad, and Zahra Yazdanparast. "Discovering the symptom patterns of COVID-19 from recovered and deceased patients using Apriori association rule mining." Informatics in Medicine Unlocked 42 (2023): 101351.
[8] Sarker, Iqbal H. "Data science and analytics: an overview from data-driven smart computing, decision-making and applications perspective." SN Computer Science 2.5 (2021): 377.
[9] Caruana, Adrian, et al. "Machine learning for administrative health records: A systematic review of techniques and applications." Artificial Intelligence in Medicine (2023): 102642.
[10] Tesio, Luigi, et al. "Interpreting results from Rasch analysis 2. Advanced model applications and the data-model fit assessment." Disability and Rehabilitation 46.3 (2024): 604-617.
[11] Patel, Aniruddh P., and Amit V. Khera. "Advances and applications of polygenic scores for coronary artery disease." Annual Review of Medicine 74 (2023): 141-154.
[12] Mohamad, Ittirit, et al. "Application of the apriori algorithm for traffic crash analysis in Thailand." Safety 9.3 (2023): 58.
[13] Wilson, Manuel, et al. "A perfect hashing to enhance the performance of Apriori algorithm." 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT). IEEE, 2023.
[14] Kohzadi, Zahra, et al. "Extraction frequent patterns in trauma dataset based on automatic generation of minimum support and feature weighting." BMC Medical Research Methodology 24.1 (2024): 1-18.
[15] Seghieri, Chiara, et al. "Learning prevalent patterns of co-morbidities in multichronic patients using population-based healthcare data." Scientific Reports 14.1 (2024): 2186.
[16] Alharith, Razan, et al. "Extraction of Association Rules from Cancer Patient’s Records using FP Growth Algorithm." ITM Web of Conferences. Vol. 63. EDP Sciences, 2024.
[17] Tenepalli, Deepika, and Navamani TM. "A Systematic Review on IoT and Machine Learning Algorithms in E-Healthcare." International Journal of Computing and Digital Systems 15.1 (2024): 1-14.
[18] Pal, Swadesh, and Roderick Melnik. "Nonlocal Models in Biology and Life Sciences: Sources, Developments, and Applications." arXiv preprint arXiv:2401.14651 (2024).
[19] Aljehani, Shahad S., and Youseef A. Alotaibi. "Preserving Privacy in Association Rule Mining Using Metaheuristic-based Algorithms: A Systematic Literature Review." IEEE Access (2024).
[20] Papageorgiou, George, Vangelis Sarlis, and Christos Tjortjis. "Unsupervised Learning in NBA Injury Recovery: Advanced Data Mining to Decode Recovery Durations and Economic Impacts." Information 15.1 (2024): 61.
[21] https://www.kaggle.com/datasets/thedevastator/hospitals-in-the-united-states-a-comprehensive-d